Natural language processing (NLP) is a branch of artificial intelligence that deals with the understanding and generation of natural language. NLP has many applications, such as machine translation, question answering, sentiment analysis, text summarization, and more. However, natural language is complex and diverse, and it poses many challenges for NLP systems.
One of the recent breakthroughs in NLP is the development of pretraining methods, which aim to learn general language representations from large amounts of unlabeled text data, and then fine-tune them on specific downstream tasks. Pretraining methods can leverage the vast amount of text data available on the web and can improve the performance of NLP systems on various tasks.
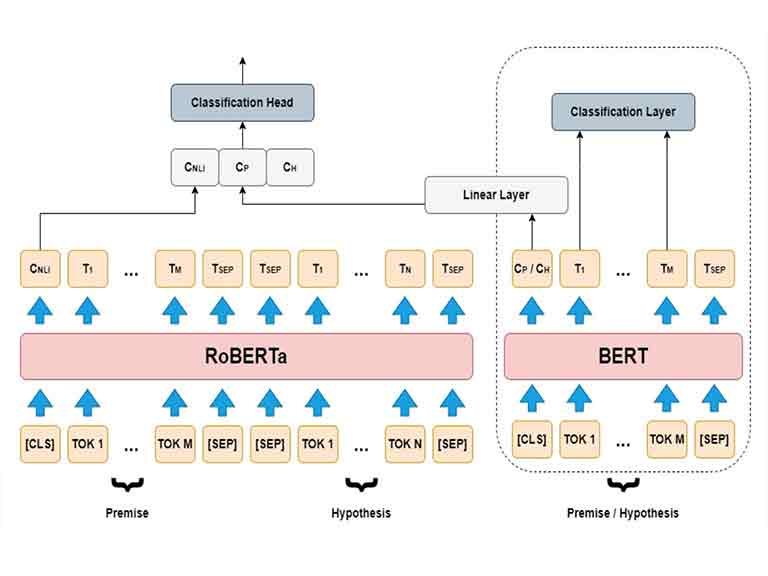
One of the most popular and influential pretraining methods is BERT (Bidirectional Encoder Representations from Transformers), proposed by Devlin et al. (2019) ¹. BERT is based on the Transformer architecture (Vaswani et al., 2017) ², which is a neural network model that uses attention mechanisms to encode and decode sequences. BERT uses a bidirectional encoder, which means that it can capture both the left and the right context of each word in a sentence. BERT also uses two pretraining objectives: masked language modeling (MLM) and next sentence prediction (NSP). MLM randomly masks some words in a sentence and asks the model to predict them based on the rest of the sentence. NSP randomly pairs two sentences and asks the model to predict whether they are consecutive or not.
BERT achieved state-of-the-art results on several NLP benchmarks, such as GLUE (Wang et al., 2018) ³, SQuAD (Rajpurkar et al., 2016) ⁴, and RACE (Lai et al., 2017) ⁵. However, BERT also has some limitations and drawbacks, such as:
- BERT is computationally expensive to train, requiring large amounts of GPU or TPU resources.
- BERT is trained on private datasets of different sizes, which makes it difficult to compare and reproduce the results of different models.
- BERT’s hyperparameters, such as the number of layers, the hidden size, the batch size, the learning rate, and the training steps, are not fully optimized, and may have a significant impact on the final results.
- BERT’s pretraining objectives, especially NSP, may not be optimal for learning general language representations, and may introduce some noise or bias into the model.
To address these issues, Liu et al. (2019) ⁶ proposed RoBERTa (Robustly Optimized BERT Pretraining Approach), which is a modified and improved version of BERT. RoBERTa introduces several changes to BERT, such as:
- RoBERTa trains the model longer, with bigger batches, over more data. RoBERTa uses more than 10 times the amount of data that BERT uses and trains the model for longer steps with larger batch sizes and learning rates.
- RoBERTa removes the NSP objective, and only uses MLM as the pretraining objective. RoBERTa argues that NSP is not a good proxy for sentence-level understanding, and that it may hurt the performance of downstream tasks that require sentence or paragraph-level reasoning.
- RoBERTa trains on longer sequences, up to 512 tokens. RoBERTa increases the maximum input length from 128 to 512 tokens, which allows the model to capture more long-range dependencies and context information.
- RoBERTa dynamically changes the masking pattern applied to the training data. RoBERTa uses a different masking strategy from BERT, which randomly masks tokens with a probability of 15%, but also dynamically changes the masked tokens during the training process. This prevents the model from memorizing the position of the masked tokens and encourages the model to learn from the whole sentence.
RoBERTa shows that these simple modifications can significantly improve the performance of BERT on various NLP tasks. RoBERTa matches or exceeds the results of every model published after BERT, and achieves state-of-the-art results on GLUE, RACE, and SQuAD. RoBERTa also demonstrates the importance of carefully tuning the hyperparameters and training data size and raises questions about the source of the improvements reported by other models.
In this article, we will review the main components and contributions of RoBERTa, and compare it with BERT and other pretraining methods. We will also discuss some of the implications and limitations of RoBERTa, and suggest some possible directions for future research.
BERT Review
Before we dive into the details of RoBERTa, let us first briefly review the main features and components of BERT, which is the basis of RoBERTa. BERT stands for Bidirectional Encoder Representations from Transformers, and it is a neural network model that uses the Transformer architecture to learn general language representations from large amounts of unlabeled text data.
Transformer Architecture
The Transformer architecture was proposed by Vaswani et al. (2017) ² as a novel way to encode and decode sequences, especially for machine translation. The Transformer consists of two parts: an encoder and a decoder. The encoder takes a sequence of tokens as input, and outputs a sequence of hidden states, one for each token. The decoder takes the encoder’s output and a target sequence as input and generates a new sequence as output.
The key feature of the Transformer is the use of attention mechanisms, which allow the model to focus on the most relevant parts of the input and output sequences. Attention mechanisms compute a weighted sum of the hidden states, where the weights are determined by the similarity between the query and the key vectors. There are different types of attention mechanisms, such as self-attention, cross-attention, and multi-head attention. Self-attention computes the attention weights within the same sequence, while cross-attention computes the attention weights between two different sequences. Multi-head attention splits the query, key, and value vectors into multiple heads, and computes the attention weights for each head separately, and then concatenates the results.
The encoder and the decoder of the Transformer are composed of multiple layers, each consisting of two sub-layers: a multi-head self-attention layer, and a feed-forward layer. The encoder also adds a residual connection and a layer normalization after each sub-layer. The decoder adds a third sub-layer, which is a multi-head cross-attention layer that attends to the encoder’s output. The decoder also adds a masking mechanism, which prevents the model from attending to the future tokens in the target sequence.
The Transformer architecture has several advantages over the traditional recurrent or convolutional neural network models, such as:
- – The Transformer can capture long-range dependencies and context information, as it can attend to any token in the input or output sequence, regardless of the distance.
- The Transformer can parallelize the computation of the hidden states, as it does not depend on the previous or next tokens, unlike the recurrent or convolutional models.
- The Transformer can learn complex and non-linear relationships between the tokens, as it uses multiple attention heads and feed-forward layers.
- The Transformer architecture has been widely adopted and extended by many NLP models, such as BERT, GPT, XLNet, and T5. However, the Transformer also has some drawbacks, such as:
- The Transformer requires a large amount of memory and computation resources, as it has a high number of parameters and operations, especially for long sequences.
- The Transformer may suffer from the vanishing gradient problem, as it has a deep architecture with many layers and sub-layers, which may make the optimization difficult.
- The Transformer may not be able to capture the sequential and temporal information of the input and output sequences, as it does not have any recurrence or convolution mechanism.
BERT Model
BERT is a neural network model that uses the Transformer architecture to learn general language representations from large amounts of unlabeled text data. BERT is based on the encoder part of the Transformer, and it uses a bidirectional encoder, which means that it can capture both the left and the right context of each word in a sentence.
BERT uses two pretraining objectives: masked language modeling (MLM) and next sentence prediction (NSP). MLM randomly masks some words in a sentence and asks the model to predict them based on the rest of the sentence. NSP randomly pairs two sentences and asks the model to predict whether they are consecutive or not.
BERT uses a special token [CLS] at the beginning of each sentence, and a special token [SEP] to separate the sentences. BERT also uses a positional embedding to encode the position of each token in the sequence, and a segment embedding to encode the sentence identity. BERT concatenates the token, position, and segment embeddings as the input to the encoder.
BERT has two versions: BERT-base and BERT-large. BERT-base has 12 layers, 768 hidden units, and 12 attention heads, resulting in 110 million parameters. BERT-large has 24 layers, 1024 hidden units, and 16 attention heads, resulting in 340 million parameters. BERT is trained on two datasets: BooksCorpus (Zhu et al., 2015) and English Wikipedia, which have a total of 3.3 billion words.
BERT can be fine-tuned on various downstream tasks, such as classification, question answering, and natural language inference. BERT achieves state-of-the-art results on several NLP benchmarks, such as GLUE, SQuAD, and more.